[모두의 딥러닝] lec 10-2. Initialize weights 잘 해보자
Vanishing gradient 문제
- 해결법
1. ReLU
2. Geoffrey Hinton's summary of findings up to today 중
"We initialized the weights in a stupid way."
Cost function
- 같은 코드, 같은 Activation function을 실행하더라도 cost 함수가 좀 달라질 수 있다.
--> weight을 입력할 때, random값을 주었기 때문. (0~1 사이)
W의 초기값을 0으로 주는 경우

- w는 chain rule에 사용됨.
- x의 기울기는 0이 될 것.
- x의 이후 기울기는 0이 되어 기울기(gradient)가 사라지는 문제 발생할 것.
W의 초기값을 현명하게 주어야 할 필요성!
- 절대로 모든 초기값을 0을 주지 않는다.
--> 네트워크가 깊어질수록 학습이 잘 되지 않는다.
- Challenging issue
- Hinton et al. (2006) "A Fast Learning Algorithm for Deep Belief Nets"
: Restricted Boatman Machine (RBM)
==> RBM을 사용해서 초기화를 시킨 네트워크를 DBN(Deep Belief Net)
RBM Structure
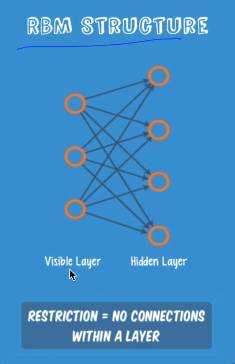
- 앞 부분에 입력단, 뒷 부분에 출력단이 있음.
- Restrict 라고 하는 이유) 노드들끼리 연결이 되지 않고 앞, 뒤로만 연결이 되어있어서
입력값이 있을 때 어떻게 되는지?
- 두 가지 Operation
: 목적) 입력을 재생산: Recreate Input
1. Forward = W, b를 가지고 입력값과 곱하여 값을 낸다. 그 값을 보냄.
: 값에 따라 값이 작으면 activation이 되고/안되고 할 것임.

2. Backward = 똑같은 일을 반대로, 거꾸로 한다. W은 그대로 사용.

==> 비교) 첫번째 주었던 값 (x)와 받은 값을 거꾸로 쏜 생성된 (xhat) 값을 비교
이 둘의 차가 최저가 되도록 W의 값을 조정한다!!
--> 이 Operation 수행 시 둘의 값이 비슷해지도록!

- KL Divergence = compare actual to recreation: 거리를 구할 때 사용하는 연산자
= encoder(forward에서 사용)/decoder(backward에서 사용)
= auto encoder/decoder 라고 하기도 함
RBM으로 W을 초기화하는 방법?
- 많은 layer 중 layer 두 개만 본다. encoder, decoder하여 초기값이 내가 준 값과 유사하게 나오는
W을 학습시킴.
: Apply the RBM idea on adjacent two layers as a pre-training step
- 쭉 진행
: Continue the first process to all layers
- This will set weights
- Ex: Deep Belief Network(DBM) --> Weight initialized by RBM
1. Pre-training 과정
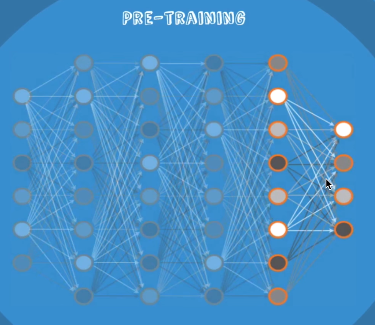
- label도 필요 없이 x 값만 있으면 됨.
- 두 layer를 가지고 RBM을 돌린다.
--> 입력과 출력이 비슷해지는 W들을 학습시키자.
- 계속 두 layer씩 마지막까지 실행
- 들어있는 W들이 초기화된 값들임. 이 값들을 초기값을 사용함.
--> 잘 됨!
2. Fine Tuning
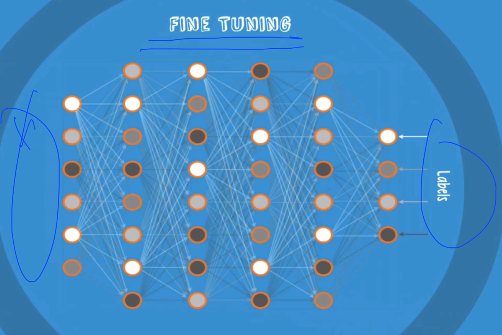
- 실제로 학습하듯이 학습 데이터로 실제 label을 가지고 학습시킴.
- 학습할 때 데이터를 많이 사용하지 않아도 빠르게 학습 되었다. --> fine tuning
: 이미 W의 초기화가 잘 이루어졌기 때문.
좋은 소식
- 복잡한 RBM을 쓰지 않아도 된다!
: No need to use complicated RBM for weight initializations
- 간단한 초기값을 주어도 된다!
: Simple methods are OK
--> Xavier initialization: 2010년 논문
: 노드에 몇개 입력, 몇개 출력인가에 비례하여 초기값을 주는 것
Xavier/He initialization
- Makes sure the weights are 'just right', not too small, not too big
- Using number of input (fan_in) and output (fan_out)

- (2010) 기존 아이디어: 좋은 값을 선택할 때 입력 몇개 출력 몇개에 따라 좌우된다.
fan_in, fan_out 값을 sqrt한 fan_in 값으로 나눈 것을 초기값으로 줌
--> RBM을 한 것보다 더 잘된다!!
- (2015)
초기값을 (2010)의 것에 fan_in/2를 하면 잘된다!
더 복잡하게 구현해놓은 것

Activation functions & initialization on CIFAR-10
- 이때까지 연구한 여러 초기화하는 방법들

아직 연구하고 있는 분야임
- 우리는 완벽한 초기값을 잘 모르기 때문에
- 여러가지를 실행시켜보아야 한다.
: Batch normalization
: Layer sequential uniform variance
: ...
==> Geoffrey Hinton's summary of findings up to today 중
- We initialized the weights in a stupid way
- We used the wrong type of non-linearity
는 해결이 되었다.