
[모두의 딥러닝] lec 07-1. Application & Tips: 학습 rate, Overfitting, 그리고 일반화 (Regularization)
1. Learning rate 조절 방법
Gradient descent 알고리즘 안 learning rate (α)

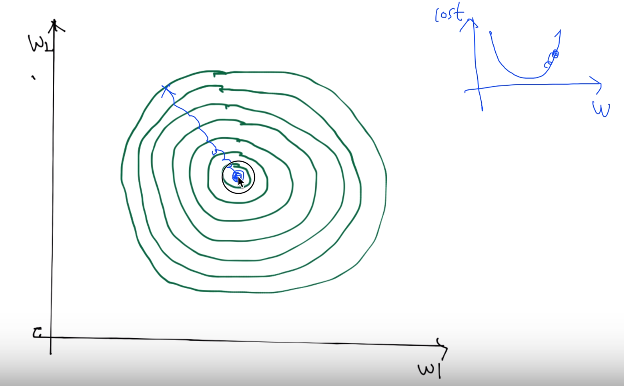
Large learning rate: overshooting
어떤 learning rate의 값을 크게 주었다고 생각해보자.

overshooting: learning rate을 주었을 때, cost 값이 줄어들지 않고 바깥으로 튕겨나갈 때
---> learning rate을 의심해봐야 함.
Small learning rate: takes too long, stops at local minimum

Try several learning rates
- learning rate을 정하는 데 특별한 답은 없음
- 처음에는 보통 0.01로 시작
--> 발산이 된다면 값을 줄이고, 너무 늦게 움직이면 좀더 크게 하기
- Observe the cost function
- Check it goes down in a reasonable rate
2. Data preprocessing
Data preprocessing for gradient descent
gradient descent가 weight이 2개 있다고 생각해보자.
ex) 데이터 값 중 x1, x2가 서로 간 값의 큰 차이가 나게 된다면? (등고선으로 표현)
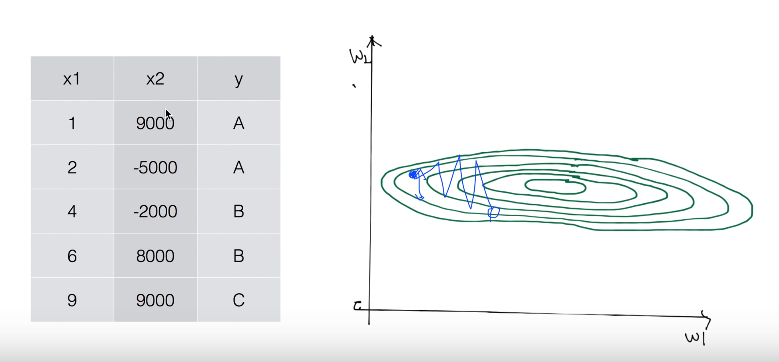
조금해서 잘못해서 밖으로 나가게 되면 값이 튕겨나갈 수 있음. (주의)
normalize: 데이터 값에 큰 차이가 있을 경우,
zero-centered data: 데이터의 중심이 0으로 갈 수 있도록 해주는 방법
normalized data: 값의 범위가 특정 범위 안에 항상 들어가도록 normalize하는 방법
learning rate도 잘 잡은 것 같은데 학습이 일어나지 않고 cost함수가 이상한 동작을 보일 때,
값이 많이 차이가 나거나 data preprocessing을 하지 않았는지 살펴보기!
Standardization
x의 값을 계산한 평균과 분산값으로 나누면 된다.
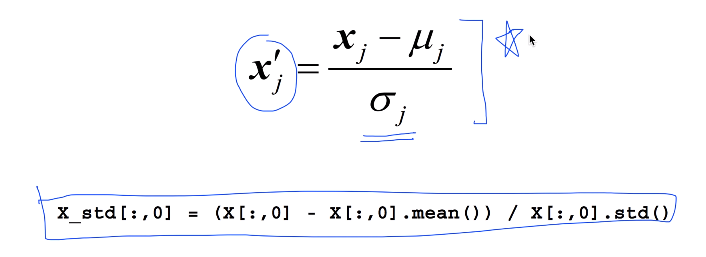
normalization 하나 형태 선택해서 해보기
3. ML의 큰 문제인 overfitting(중요) 방지 방법
ML은 학습을 통해 모델을 만들어간다. BUT
- Our model is very good with training data set (with memorization)
- Not good at test dataset or in real use

- model1
좀 더 일반적인 모델: 다른 데이터가 들어와도 잘 적용 가능
이렇게 된다면 좋은 모델
- model2
학습 데이터에 맞추기 위하여 model을 좀 꼬여서? 힘들게 만든 경우
갖고 있는 데이터에만 초점을 맞춘 모델
실제 사용 시 정확도가 떨어질 수 있음.
==> Overfitting
Solutions for overfitting
- more training data!
- reduce the number of features: 중복된 것이 있으면 줄이기
- regularization
Regularization
- Let's not have too big num in the weight
가지고 있는 weight이 너무 큰 값을 가지지 않게 하기.
decision boundary를 특정 데이터에 맞게 구부리는 것을 overfitting이라고 함.
구부리지 말고 펴자는 것
편다 = weight이 작은 값을 갖는 것
구부린다 = weight이 큰 값을 갖는 것
cost 함수를 최소화 시키는 것이 우리의 목표였는데, cost 함수 뒤에 term을 추가시키자!

regularization strength
0 --> 쓰지 않겠다.
1 --> 굉장히 중요하게 생각한다.

이 값을 cost 함수와 더한 후 최소화시키는 것.
'인공지능' 카테고리의 다른 글
| [모두의 딥러닝] lab 07-1. training/test data set, learning rate, normalization (0) | 2019.05.03 |
|---|---|
| [모두의 딥러닝] lec 07-2. Application & Tips: Training / Testing data sets (0) | 2019.05.03 |
| [모두의 딥러닝] lab 06-2. TensorFlow로 Fancy Softmax Classification 구현하기 (0) | 2019.05.03 |
| [모두의 딥러닝] lab 06-1. TensorFlow로 Softmax Classification 구현하기 (1) | 2019.04.10 |
| [모두의 딥러닝] lec 06-2. Softmax classifier의 cost 함수 (0) | 2019.04.08 |
댓글