
[모두의 딥러닝] lec 07-2. Application & Tips: Training / Testing data sets
머신러닝 모델이 얼마나 잘 동작하는 지 확인하는 방법
Performance evaluation: is this good?
Evaluation using training set?
training set으로 모델을 학습시킴.
다시 training set으로 모델을 평가하게 되면 답을 하거나 예측을 할 수 있을 것.
이것이 공정한 것일까?
--> 이렇게 하면 100% 완벽한 답을 할 것이다.
- 아주 나쁜 방법
Training and test sets : 좋은 방법
시험을 보는 것과 똑같다.
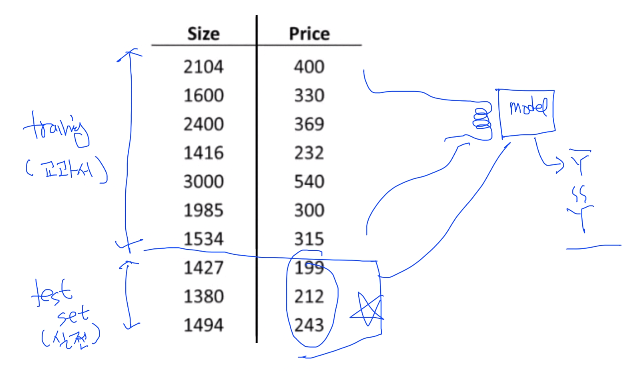
test data set은 숨겨져 있다고 가정. 볼 수 없다. (중요)
training set만을 가지고 model을 학습시킨 후, model에 test set을 실험해보자!
training의 결과 값인 Yhat과, test의 결과 값인 Y를 비교
Training, validation and test sets
알파, 람다(regularization을 얼마나 강하게 할 것인가) 값을 tuning할 필요가 있을 경우
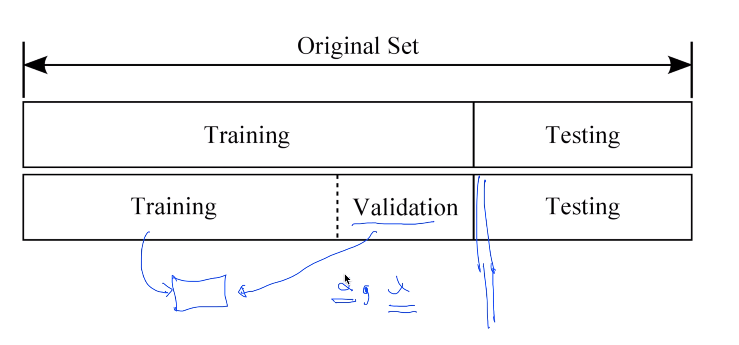
training set을 두 개로 나눔.
- 완벽한 training set / validation set
training set으로 먼저 model을 학습시킨 후, validation set을 가지고 알파, 람다 값을 어떤 것을
쓰면 좋을 지 튜닝, 모의 시험 하는 것.
==> 이후 testing set으로 model 평가.
ex) 모의 고사 (validation set) / 실제 시험 (testing)
Online learning
데이터 셋이 많은 경우, 한번에 다 넣어서 학습시키기 힘들 때 (다 메모리에 올리기 힘듦)
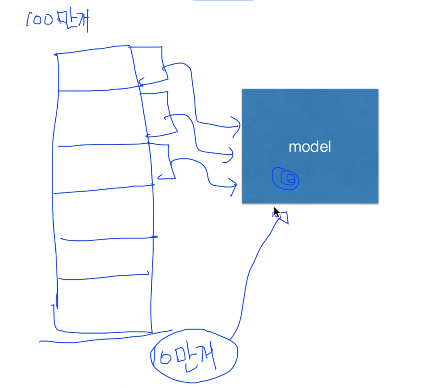
ex) training set 100만개 --> 10만개의 단위로 쪼개어 각각 학습시킴
첫번째 학습시킨 결과가 model에 그대로 남아 있어야 함. 이후의 학습 결과도 추가되어야 함.
나중에 새 데이터가 추가되면, 이전 데이터를 또 다시 학습시키지 않고 추가된 데이터만 추가로 학습시킬
수 있어서 좋음
MINIST Dataset
사람들이 손글씨로 적은 숫자들을 컴퓨터가 알아볼 수 있나?
미국에서 사람들이 쓴 우편번호를 compact시키기 위하여 사용.

training set / test set (image / label)
Accuracy
model에서 예측한 Yhat과, 실제 Y를 비교하여 확률로 나타내기
- How many of ur predictions are correct?
- 이미지 정확도: 95% 이상
댓글